python爬取琳琅社区整站视频操作教程
该项目用于爬取琳琅社区整站视频(仅供学习)
主要使用:python3.7 + scrapy2.19 + Mysql 8.0 + win10
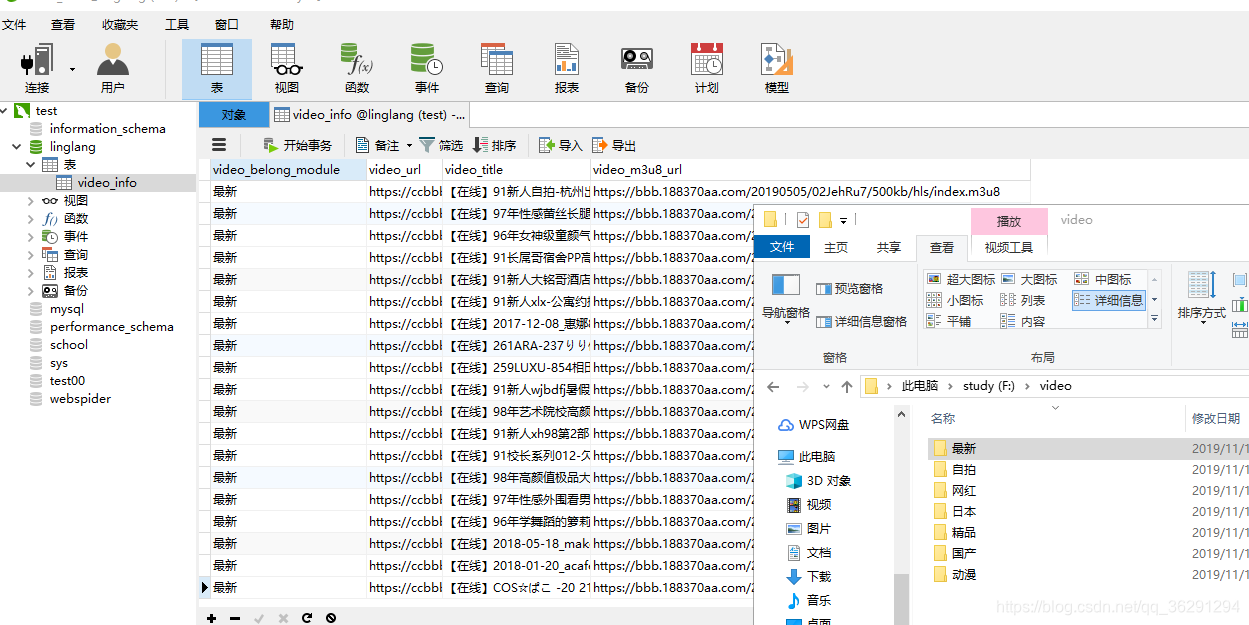
首先确定需要爬取的内容,定义item:

然后编写爬虫文件:构造初始url的解析函数,得到琳琅网站的视频分类请求,并在本地生成存储的主目录

定义具体模块页面的解析函数,支持分页爬取:


返回item给管道文件:

实现一个去重管道:

再实现将数据存入mysql的存储管道,此处也可选择其他种类数据库进行存储:

其实呢,到这已经能够进行爬取了。但是我们利用scrapy对该网站频繁发起这么多次请求,对方服务器判定我们为爬虫时,会强行关闭与我们之间的连接。
虽然scrapy会将这些没有爬取成功的请求重新放回调度器,等待之后连接成功再发送请求,但是这样会浪费我们一些时间。
为了提高效率,当本地请求失败后,我们可以在下载中间件中使用动态代理重新发起请求:

最后启动爬虫,等待爬虫结束,查看数据库,满满的收获~
关键词: 琳琅社区






- 塞尔达传说王国之泪后期什么武器装备好用2023-05-25
- 即时看!塞尔达传说王国之泪监视堡垒女神像2023-05-25
- 通讯!塞尔达传说王国之泪拉聂耳山女神像在2023-05-25
- 世界速读:名为“七国集团” 实则“1+6”2023-05-25
- 预计9月底量产 全新北京BJ40国内谍照2023-05-25
- TCL在珠海横琴成立科技公司# 注册资本3亿-2023-05-25
- Reno10 Pro+影像实拍体验2023-05-25
- 将登陆PSVR2头显,VR版《生化危机4重制版》2023-05-25
- 今日讯!小米Civi3预热大存储2023-05-25
- 有意见 | 50项更新亮相微软Build大会,Wi2023-05-25
- 天天资讯:北科建青岛蓝色生物医药产业园:2023-05-25
- 青春力量 | 从跨界转行到口碑相传2023-05-25
- 如果幸福有形状,它会像花儿一样_天天新要2023-05-25
- 4月杭州房地产市场报告:土地市场维持高热2023-05-25
- 全球快讯:合肥三批次土拍热度不减,4宗宅地2023-05-25
- 原神恒动械画蒙德之一攻略 蒙德之一修复机2023-05-25
- 中国联通非常重视5G RedCap发展 集团科创2023-05-25
- 米家高速吹风机H501 轻盈速干 299元普惠2023-05-25
- 全球看热讯:英大泰和人寿董事长侯培建今年2023-05-25
- 投入超200亿!未来三年新增上万就业——京2023-05-25
- 金辉上海公司营销副总孙洪跳槽不少 这次2023-05-25
- 世界热资讯!“摆摊”送服务 “创文”补短2023-05-25
- 水性紫外线吸收剂 关于水性紫外线吸收剂介2023-05-25
- 码农一枚,个人收入在全社会属于前列,但孩2023-05-25
- 塞尔达传说王国之泪正常方法怎么快速赚钱2023-05-25
- 传感器的主要功能是什么?传感器分类2023-05-25
- 微信视频号怎么发视频?微信视频号怎么推广2023-05-25
- 天天快看点丨麻城几个火车站2023-05-25
- yjv电缆是什么意思?yjv电缆的绝缘层是什么2023-05-25
- 无叶风扇是怎么出风的?无叶风扇原理2023-05-25
新闻排行
精彩推荐
- 努比亚Z40SPro星空典藏版开售 搭配居中打孔设计
- 首批骁龙8Gen2机型发布时间曝光 11月底两家厂商率先发布
- iQOO11系列最高将配200W快充 10分钟可将4700mAh容量电池充满
- AOC公布CU34G2XP带鱼屏显示器 采用VA面板165Hz刷新率
- 三位知情人士:苹果已暂停几乎所有招聘,直至明年9月
- 荣耀X40琥珀星光配色开售 支持10亿色彩显示
- 小米笔记本Air13翻转本开售 搭载13.3英寸E4OLED屏
- 小米RedmiA70电视开售 采用金属全面屏设计
- 华硕开设首个AI智能工厂 提高产品质量
- 苹果iPadPro2022款/iPad10正式开售 支持ApplePencil悬停功能
 营业执照公示信息
营业执照公示信息